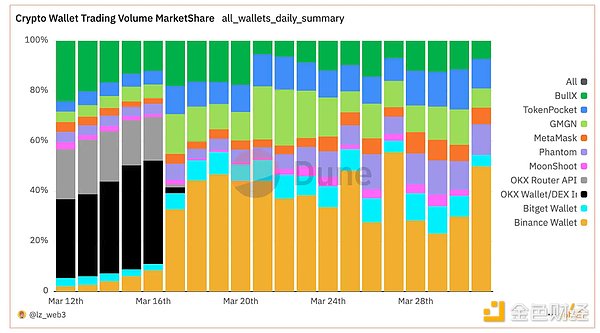
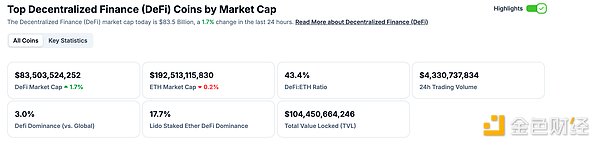
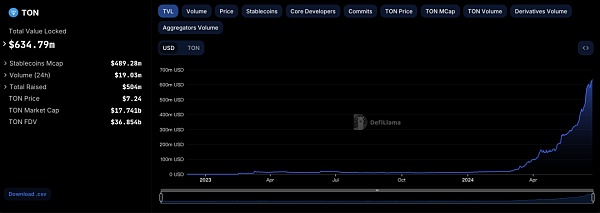
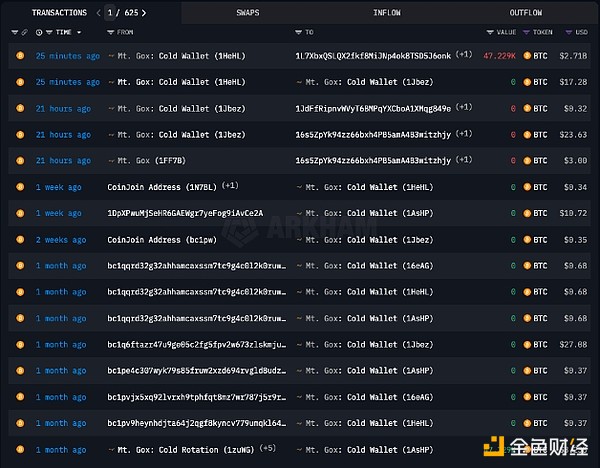
作者:陈默 来源:cmdefi
Justine Moore 花了6个月的时间做一项实验,每天与ChatGPT交流,不断分享个人想法和情感,试图创建一个真正理解自己的“AI大脑”,结果AI的能力完全超出预期,她列举了以下几个场景:
1. 与他人沟通:通过使用大语言模型(LLM),可以帮助我们更清晰地传达复杂的想法,大幅提升沟通能力。
这一点本身我自己也在用,目前我用到的AI最强能力,我觉得就是总结和沟通能力,如果你的总结能力比较欠缺,特别是对于在需要把一件事情或是一个项目给别人讲清楚的情况下,利用AI学习总结和沟通能力真的是太强了。
2. 自我理解:AI大脑能够很好地“心理分析”你,帮助你更清楚地认识自己的优势和弱点,纠正认知偏见。
3. 与应用程序交互:AI大脑可以被带入其他应用,解锁真正个性化的体验,比如一个完全理解你风格的写作助手,或为你量身定制的工作或社交工具。
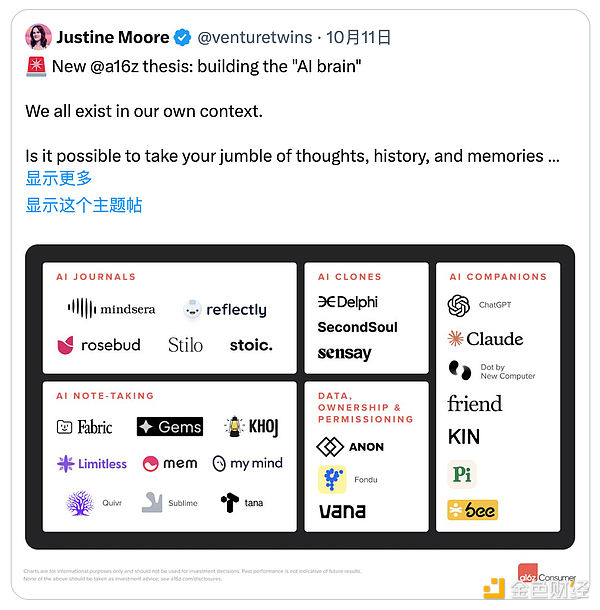
实际上如果你是一个重度AI使用者,可能已经有过类似的体验,至少我觉得未来每个人都会有一个适配自己的AI大脑。
1. 用户数据的完整性与质量
要让AI大脑真正理解你,首先需要大量且高质量的个人数据。这包括你的历史对话、行为记录、情感倾向、偏好和决策等。数据越丰富越完整,AI大脑越能够完美捕捉你的思维模式和个性。
2. 数据的私密性与安全性
个人数据的隐私保护至关重要,因为它已经学习了你大量的生活习性、性格喜好,甚至弱点缺陷。在构建“AI大脑”时,用户需要对数据有完全的控制权,确保这些数据不会被滥用或泄露。毕竟,你的AI大脑最好不要让别人入侵。
3. 透明的模型训练和数据使用机制
一个真正理解自己的AI大脑,透明度是关键。用户应该知道他们的数据如何被使用、AI模型如何训练,这也可以被理解是安全性的一种。
在Justine的理念中,也基于以上3条,AI大脑应该完全掌握在用户手中,避免大科技公司对数据的垄断和利用。
所以,去中心化的架构可能成为一条通道,它可以通过让用户成为数据和AI模型的实际所有者,确保用户在数据和AI模型的整个生命周期中都保持对其贡献的控制和利益相关性。
这一方案的核心理念是 -赋予用户对数据的完全主权,这基本与“AI大脑”的理念完全契合。
Vana引入“非托管数据”的概念,确保数据仅用于用户授权的操作。用户始终拥有对自己数据的控制权,不会被平台或第三方托管。
实现方式就是,数据在贡献给服务器之前会进行加密处理。每个用户将自己的数据通过服务器的公钥进行加密,确保即使数据被传输到集体服务器或用于AI训练时,数据本身仍然是保密的,只有拥有解密密钥的参与者才能解密和访问数据。
这一点不仅解决了用户的数据主权和隐私性,也为数据质量奠定了基础,这也很重要,因为保证了隐私性,用户才能没有顾虑的提供真实数据,配合Vana区块链的贡献证明(Proof-of-Contribution)机制,加入了Crypto已经深入骨髓的代币激励模型,能够让用户更加有动力去提供高质量数据。
综合来说,Vana DataDAO 主要解决的就是数据主权问题,当然包括数据隐私和安全。事实上想训练一个AI助手并不难,很多训练语言模型的API都能够提供这种环境,但未来我们的需求是否只会满足于一个“助手”?AI 就像一个潘多拉魔盒,打开之后释放出的魔力之强大可能越来越让人难以拒绝,如果人类的需求上升到AI大脑、AI超级大脑的级别,关于数据主权的问题就不可避免。
转载请注明:果米财情 » 区块链 » 跟随 A16Z 进入 “AI大脑” 时代
本文仅代表作者观点,不代表果米财情立场。
本文系作者授权发表,未经许可,不得转载。

DGD今日价格(dyn今日价格)
2025-04-20
以太坊testnet(以太坊的最新美元价格)
2025-04-20
人人币在哪个平台交易(人人币今日价格)
2025-04-20
以太坊scrypt(以太坊币今日价格行情)
2025-04-20
justswap钱包授权(imtoken钱包授权)
2025-04-20
货币比特币今日价格(现货比特币价格)
2025-04-20
以太坊分红(以太坊分红一天能分多少)
2025-04-20
比特币是啥(比特币啥时候进入中国)
2025-04-20
btcv什么价格(btcv币可靠吗)
2025-04-20
点点币钱包(点点币的图片)
2025-04-20