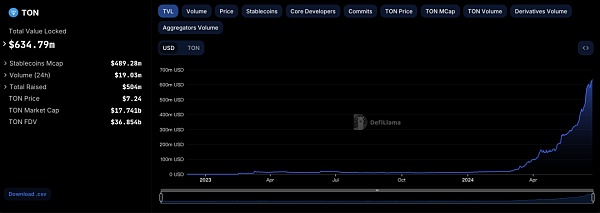
来源:登链社区
Rollups 发展迅速。最初, 典型的rollups 为以太坊的可扩展性挑战提供了短期解决方案。现在,随着技术的进步,我们正在构建下一代 rollups,这些 rollups 不仅进一步扩展以太坊,而且还保留去中心化、安全性和经济可持续性。
在一系列名为“解读下一代 L2”的四部分系列中,我们探讨了一 些新的 rollup 类型——Based rollups、Booster rollups、gigagas rollups、原生 rollups——并旨在向广泛的受众介绍这些设计。这些 rollups 代表了以太坊扩展的未来,鉴于 @2077Research 致力于使以太坊研究和开发 (R&D) 变得可访问,我们认为教育社区了解更新的 L2 设计是重要的。
我们的目标是快速介绍这些技术,并阐明相关概念。在本系列中,我们将分解每种 rollup 类型,探讨它们的设计、优点、权衡以及对以太坊路线图的整体影响。无论你是以太坊爱好者、开发者,还是对区块链可扩展性感到好奇,本系列都适合你。
第一篇文章着眼于Based Rollups——一种提议的构建 rollups 的方法,旨在减轻经典 rollups 的问题,例如排序器中心化、生命周期风险和审查阻力。我们将探索Based Rollups 的工作原理,它们提供的好处以及Based Rollups 采用的障碍。
如果 rollup 使用基于排序的方式来处理交易,则称其为Based(基于) rollup。排序是指在 rollup 中如何对交易进行执行排序。基于排序利用 Layer 1 (L1) 链的验证者集来排序交易,而不是依赖于中心化的实体(“排序器”)来对交易进行排序。
如今,传统的 rollups 有集中排序器,这导致了几个问题。这些问题包括对用户交易的审查、单点故障的风险以及 MEV 垄断(集中排序器由于对内存池的私有访问可以从用户那里提取 MEV(最大提取值))。
鉴于中心化排序的问题,以太坊社区一直在寻找替代方案。重要的是,这种替代排序设计必须满足一个关键设计目标:它们必须与其前任一样高效和快速。
基于排序和Based Rollups 是朝着这个方向迈出的积极一步,因为它们为 rollups 提供了一种新的交易排序方式,继承了以太坊的审查阻力,消除了单点故障,并避免为去中心化而牺牲速度。我们在下面描述Based Rollups 的工作原理。
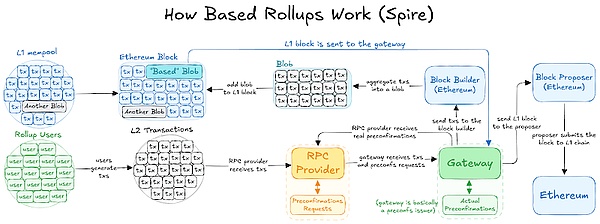 @Spire_Labs 的Based rollup 架构的描述
@Spire_Labs 的Based rollup 架构的描述基于 rollup 和任何其他类型 rollup 之间的主要区别在于交易的排序方式。在基于 rollup 中,交易排序由底层 L1 区块链管理(在这里是以太坊)。具体而言,在基于 rollup 中,“任何下一个 L1 提议者都可以与 L1 查找者和构建者一起自由地在下一个 L1 块中包含后续的 rollup 块,而无需特殊权限。
在基于 rollup 的架构中,用户的交易被指向已同意为以太坊和基于 L2 构建块的 L1 构建者。用户指示其最高交易费用,L2 捕获基础费用(根据 L2 网络拥堵情况设定)并将优先费用(支付给激励交易包含的提示)转发给验证者,后者决定交易顺序。
这种安排使以太坊不仅可以确保其生态系统的所有费用,还可以收取 L2 提示的一部分,以及交易结算的费用。将价值返回给 L1 使Based Rollups 与以太坊形成共生关系,并消除了 rollups 是以太坊寄生的观念。利用 L1 提议者为 L2 交易排序的另一个好处是,它消除了交易过程中的中介步骤。这可以通过避免需要验证来自集中或去中心化排序器的签名,潜在地导致更低的交易成本。
值得一提的是,这种成本降低并不是Based Rollups 独有的;任何使用共享排序的 rollup 都可能看到类似的好处。由于 L1 上的提议区块是无权限的,这促进了块构建者之间的竞争环境,这可能进一步降低用户的费用。

taiko Based rollup 架构的描述
由于基于 rollup 将其证明直接提交给以太坊,因此其结算本质上是在以太坊上。这意味着任何人都可以在以太坊上访问 L2 链的已验证状态。基于 rollup 不能在其底层 L1 之外进行结算。
基于 rollup 在以太坊上发布重建其链状态所需的数据,使以太坊成为其数据可用性 (DA) 层。这使得任何人都可以验证区块哈希并从区块中检索交易数据。Based Rollups 使用以太坊的共识层进行交易排序,从而消除对自身共识机制的需要。
基于 rollup 中的交易执行发生在其生态系统内的链下,这意味着基于 rollup 本身作为其自己的执行层。例如,现有的Based Rollups,如 taiko 和 SpireLabs,虽然在以太坊上结算,但在同一个 L1 上运行,但保持自己的独特执行层以执行交易。
Based Rollups 的优点包括继承以太坊的安全性和活性,潜在地通过消除额外的排序降低交易成本,使 L2 交易可以与 L1 状态进行交互的原子组合,简化架构而无需单独的共识,确保所有数据在以太坊上的数据可用性,以及提供强大的审查阻力。
不过,和加密中的一切一样,基于设计也有其担忧。Based Rollups 依赖于以太坊的性能,这可能因以太坊的区块空间限制而限制可扩展性。L2 操作仍然与 gas 成本相关,这可能是相当可观的。还有 MEV 的问题,即 L1 验证者可能会影响交易排序。与以太坊的共识和数据层的紧密关联可能限制特定用例的定制化。
在这一部分,我们回答一些关于Based Rollups 的常见问题。我们的目标是消除关于Based Rollups 的特定误解,并提供关于基于 rollup 架构各个方面的清晰信息。
大多数 MEV 使 L1 验证者受益,因为 L1 查找者和区块构建者的动力是将 rollup 块包含在它们的 L1 包中以获取这一价值,从而鼓励 L1 提议者包含这些块。目前,约 80% 的以太坊 MEV 来自拥堵,20% 来自争夺。如果 L2 MEV 反映这一点,则很大一部分可能会留在 L2。
将 L1 提议者作为 L2 排序器可以省去一个中介步骤,通过消除排序器签名验证潜在地降低成本。这种节省成本的方式不仅适用于基于 rollup,还适用于共享排序的 rollup,因为无许可的区块提议促进了竞争,可能降低费用。
是的,基于 rollup 的交易确认时间与 L1 的区块时间相关,目前为 12 秒。然而,基于 rollup 可以实现即时的预确认。这可以通过类似重质押的机制来实现,部分 L1 验证者承诺将基于 rollup 的区块包含在他们未来的 L1 区块中。这是可行的,因为验证者能够提前 32 个区块知道每个区块将由谁进行提议。
基于排序共享以太坊的活性保证,完全继承其正常运行时间。即使轻微的活性下降(例如,从 100% 降至 99%)在对抗条件下也会被利用,导致重大干扰和有毒 MEV。
基于排序可以被视为共享排序的一个专门版本。共享排序作为一个跨多个 rollup 的交易排序系统,旨在实现经济效率、更高的吞吐量以及比 L1 更快的确认。它与基于 rollup 的不同之处在于使用自己操作员进行共识,使其更复杂,并不完全依赖于以太坊的活性。
在我们“Rollups 2.0”系列的第一篇文章中,我们探讨了基于 rollup,它利用以太坊的验证者进行交易排序,为去中心化、安全性和成本效率提供了一条路径。
随着我们继续这一系列,我们将深入探讨增强型 rollup、原生 rollup 和超大规模 rollup——研究这些类型的 rollup 如何解决以太坊扩展性的不同方面。
转载请注明:果米财情 » 区块链 » 解读下一代以太坊 Layer2 解决方案(I):Based Rollups
本文仅代表作者观点,不代表果米财情立场。
本文系作者授权发表,未经许可,不得转载。